


As a senior software engineer helping companies build strong digital products and services, I am always on the lookout for modern solutions that can help with rapid iteration and scaling for optimal business impact.
This passion led me to my first introduction to AWS Lambda nearly three years ago while working on a project for a government organisation. Needless to say, I had no idea what a Lambda function was and why we needed to use it over regular server instances. Since then, it has been quite the learning journey — I now actively maintain Lambda functions with half a million invocations per hour.
In this blog post, I will be sharing my experience with AWS Lambda, how you can easily get started to create and maintain an AWS Lambda function, and finally open you up to the world of possibilities that AWS Lambda offers in the form of integration with other AWS services.
But first, a quick initiation! Before we dive into AWS Lambda, we need to understand what serverless computing can bring to the table.
What is Serverless?
Serverless is a cloud-native development that allows developers to build and run applications without having to manage servers. It is a lightweight piece of code function with dependencies that run on demand.
The key benefit here is that a cloud provider handles all the routine work of provisioning, maintaining and scaling of the server infrastructure. There are still servers in serverless, but they are abstracted away from app development. This means that developers can focus on their business logic without worrying about infrastructure management. Other benefits include:
- Event-driven workflow (“If X then Y”)
- Pay-per-execution
- Zero administration
- Auto-scaling
- Short-lived, stateless functions
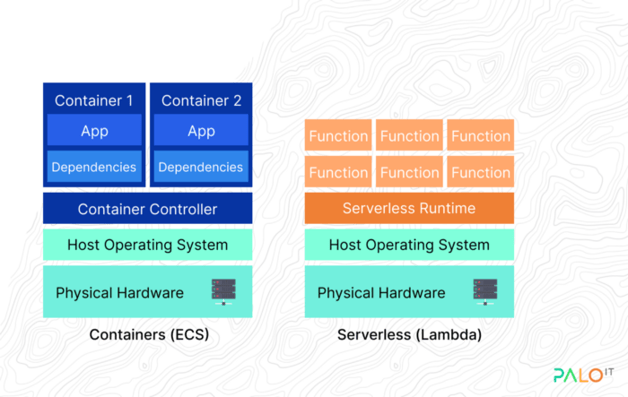 Containers vs Serverless
Containers vs Serverless
For example, a simple chatbot application can leverage serverless solutions to automatically scale for more concurrent users. Another example — with serverless, you can also perform on-demand image and video manipulation. More use cases can be found here.
Unlike containers, which take much more work to set up and maintain, serverless is ideal when development speed and cost minimisation is critical. Although you are sacrificing some control over your application, you will not have any scaling concerns in the event of peak usage and demands.
Developers can also leverage the serverless framework, an open-source library used to develop and deploy serverless applications. As this library is cloud solution independent, you can deploy the same code for all serverless solutions with minimal configurations.
Now that we have a better understanding of serverless, let’s explore AWS Lambda in greater detail.
What is AWS Lambda?
Provided by Amazon Web Services, AWS Lambda is an event-driven, serverless compute service that lets you run code without provisioning or managing servers and can extend other AWS services with custom logic.
AWS Lambda runs your code only when needed and scales automatically, capable of a few requests per day to thousands per second. As mentioned, the plus point here is that you only need to pay for the computation time you consume — there is no charge when your code is not running.
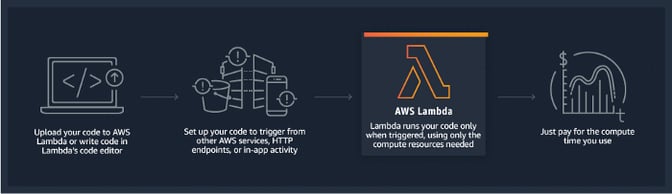 Figure from https://aws.amazon.com/lambda
Figure from https://aws.amazon.com/lambda
Similarly, Google Cloud provides a solution called Cloud Functions, while Microsoft Azure provides a solution called Azure Functions. Each of these solutions has its own pros and cons such as language support, dependencies management, code management and other key advantages. I invite you to spend some time looking at them to find out what works best for you.
Note: You still need an action to trigger your Lambda. It could be an API gateway, DynamoDB stream event, CloudWatch scheduler or another event type Lambda supports. Adding and triggering this kind of service will add more cost to your overall solution (usually a few more dollars per month).
Key Features of AWS Lambda
Setup/Maintenance
Developers can easily develop and deploy a Lambda process since there are no container configurations that you need to do. AWS also provides a code editor upon the creation of a Lambda, which you can use to directly write/edit the function instead of writing the code locally and uploading it. This will reduce the time taken to both initialise the local code repository and create a pipeline to deploy the package, making it easy to test a simple solution (this is not recommended for a longer run). On the other hand with traditional container applications, you would always need to configure your application and deploy it even if it’s to test a simple solution.
If you want to explore more about automating package deployment, I recommend checking out these solutions below:
Supported Languages/Runtimes
Lambda supports multiple languages through the use of runtimes. AWS has a list of natively supported languages/runtimes like Java, Go, PowerShell, Node.js, C#, Python, and Ruby. It also provides a runtime API that allows you to use any additional programming languages to author your functions. By creating a custom runtime environment, most cutting edge languages can be integrated with AWS Lambda. Here are some examples:
Dependencies
All projects have external dependencies. They rely on libraries that aren’t built into the language or framework. For example, most of the languages for application logging or image processing require external libraries. Another example is a separate large CSV or JSON file. For this kind of task or functionalities, we use dependencies.
When you deploy using traditional servers, it’s pretty much straightforward. You can install the package and deploy it. Fortunately, it’s the same for AWS Lambda functions.
Additionally, AWS supports dependency sharing within Lambda. A Lambda layer is an archive containing additional code, such as libraries, dependencies, or even custom runtimes. When you include a layer in a function, the contents are extracted to the /opt directory in the execution environment. You can include up to five layers per function, which count towards the standard Lambda deployment size limits. This makes it easy to share and maintain the dependencies between AWS accounts.
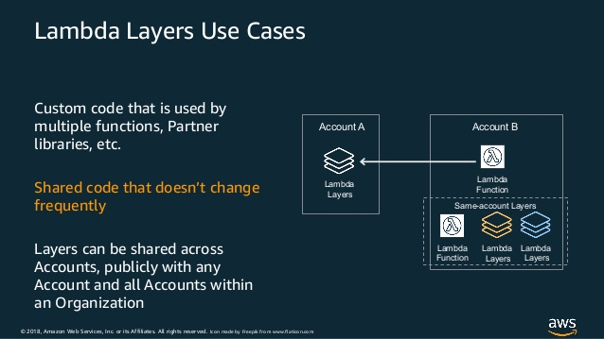 Figure from Amazon Web Services
Figure from Amazon Web Services
Performance
Naturally, users don’t want to use a slow system. Therefore, performance is a key measurement of the user engagement score. There are three main factors that greatly affect AWS Lambda performance — cold start time, execution time, and concurrency. These three issues are directly connected to the lifespan of each function and how you can utilise functions.
- Cold start and warm start
Cold start is the initial start of the Lambda function. Every cold start request has to go through a few steps to execute the function.
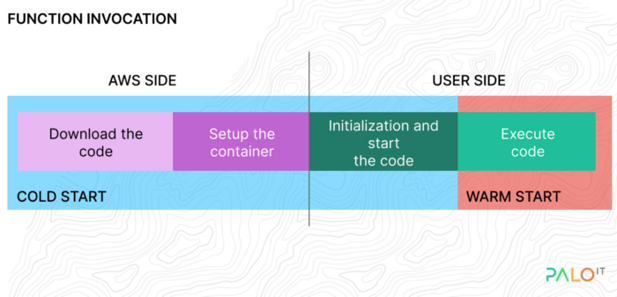
The diagram above shows that part of the cold start process is managed by AWS (code loading, container creation). Because of this, the possibilities for a user to optimise the cold start are a bit limited.
After the invocation, functions stay warm for an undeclared amount of time (generally five to seven minutes). Subsequently, the function instance is killed and the next invocation requires a new instance to be created and initialised. This cold start adds time and cost to your operations. The initialisation of your function can change depending on the runtime language and language version you choose.
A more in-depth explanation can be found here: Cold start / Warm start with AWS Lambda.
- Execution time
Lambda functions are allowed to run for up to 15 minutes for each invocation. This is a hard limit that you can’t change. It also doesn’t matter why a function runtime is long, whether your function is waiting for responses, or if it requires extensive computation. Because of this limit, you should consider using a server instance rather than a Lambda for long-running tasks.
- Concurrency
With Lamba, each function instance can only be invoked one at a time. If you invoke it again during runtime, a new instance is created up to your concurrency limit. For an initial burst of traffic, your functions’ cumulative concurrency can reach an initial level of between 500 and 3000. These quotas also vary by region. For more concurrent instances, you must request AWS to increase the number. If you do not, all invocations beyond the limit are throttled.
Security
By default, Lambda runs on an IAM role with permissions to operate. This role needs to have correct permissions to run the Lambda and use/communicate with other services like S3, CloudWatch, and DynamoDB. This prevents the Lambda function from accessing unnecessary resources. Another feature AWS provides for Lambda is attaching the Lambda to a Virtual Private Cloud (VPC). This will restrict public access to the Lambda function.
Monitoring
AWS has numerous monitoring and debugging tools that a Lambda function can leverage to monitor performance, filter logs, analyse and debug. CloudWatch Metrics, CloudWatch Logs, AWS XRay and AWS Config are the most used services.
CloudWatch Metrics
By default, a Lambda function comes with a set of metrics on a monitoring dashboard. This dashboard displays important metrics like the number of invocations, duration of the Lambda functions and concurrent executions.
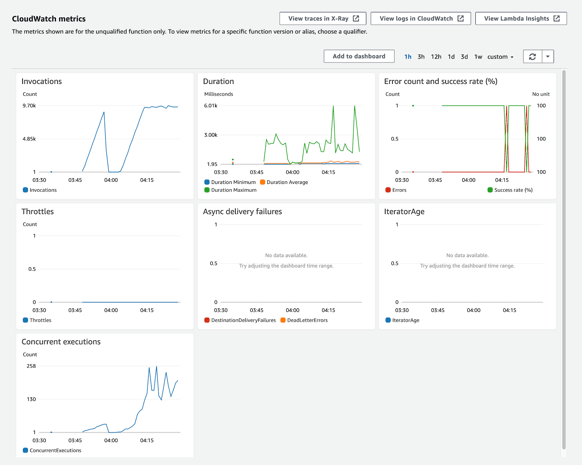 Figure from the actual project I'm working on
Figure from the actual project I'm working on
CloudWatch Logs
If you are using application logs with Lambda functions, all of them end up in CloudWatch logs. CloudWatch logs are used to real-time monitor, store, and access your log files. CloudWatch Logs provides more services, namely insights and a dashboard, that are useful for monitoring, searching, and analysing your log data.
Conclusion
With serverless solutions, your teams gain efficiency by reducing development time at the cost of some control and visibility, allowing you to focus your time on building the best product possible and getting your products to market faster.
Although there are several serverless solutions available in the market, AWS Lambda is perhaps the best one out there and is known for powering unique use cases in enterprises around the world with its multitude of integrations — from running core cloud platforms to extending legacy applications, event-driven systems and even enabling modern features like recommendation engines.
If you would like to get started or learn more about serverless solutions or AWS Lambda, I invite you to reach out to me and we can keep the discussion going!


